Packages, Libraries and Maven
Background Material
Introduction
A famous quote relating to scientific progress is, attributed to Sir Isaac Newton (1676) is: "If I have seen further it is by standing on the shoulders of giants."
This quote refers to the idea that the discovery of scientific truth is built upon previous discoveries. When we write code in a high level language such as Java, this quote applies as well: many of the built-in data structures and classes have been designed for us, ready to use. This way, we do not need to implement an ArrayList ourselves, but can use the work others have done before us.
While the standard library that comes with Java contains many useful classes that can help us write great and useful programs, there are also many things not immediately supported. Think about matrix operations, solving mathematical optimization problems or performing statistical tests.
Packages
A large project can have anywhere between dozens and thousands of classes. At some point, it can become a challenge to manage all classes if they are kept in the same folder. To overcome this issue, the Java language has a feature called packages, which can be regarded as a kind of folder for classes and interfaces. Some of the packages you may have seen are java.util and java.io. Larger software projects typically create their own packages, putting classes that intuitively belong together in the same package. For those kinds of projects, the packages usually start with a reverse URL, such as org.apache.commons.
If you don’t define a package for your classes, they are considered to be part of the default package. If you want to use classes that are in a different package than the class you are currently writing, you need to import those classes. That is why many files start with lines such as import java.util.ArrayList; at the top a file.
Tools such as Eclipse, Netbeans and IntelliJ typically provide ways to organize the imports at the top of the file automatically. For example, if a type is missing in Eclipse, hovering the mouse on the error may make code suggestions such as “Import ...”, which adds the relevant import statements at the top of our file. Furthermore, Eclipse supports the Organize Imports feature in the Source menu. Using this option usually adds all required imports. There is usually a key you can use while programming: on Windows this is Ctrl+Shift+O.
Note that in some cases, different packages may contain classes with the same name. An important example is the distribution between the List interface in the package java.util that is the interface implemented by list data structures such as ArrayList and LinkedList, while the List class from the java.awt package is used to present a graphical list in a graphical user interface.
Maven and Dependency Management
When the Java Runtime Environment needs to create objects, it searches for the classes of these objects in the classpath, that determines which classes are available or not. It is possible to manually download .jar files that contain relevant classes and configure your project to add the classes in those jar files to your classpath, so that they become available for use.
In particular when you want to use multiple libraries, or in case some of your libraries require other libraries themselves, manually downloading jar files becomes cumbersome. Many popular languages, including Python and R, provide nice ways to define which libraries you want to use, and then automatically download the required files and add them to your project.
One tool that can do that for your Java projects is Maven https://maven.apache.org/ (the most popular alternative being Gradle, https://gradle.org). Most good IDE’s, including Eclipse, have Maven support built in, so you typically don’t need to install Maven yourself. Maven is a project management tool with dependency management as one of the features. Dependency management allows you to define on which projects/libraries your project depends, and can handle the hard work of downloading those libraries and configuring your project to make those libraries available. Even if the libraries you depend on have other dependencies themselves, Maven will be able to figure out which .jar files are required, download everything that is necessary, and configure your project as required.
When a Java project is configured as a Maven project, the root folder of the project will contain a file pom.xml, which refers to the project object model: data that describes all relevant information for your project. Every Maven project has at least the following three properties:
- groupId: refers to the creators of the package, library of project. Examples are
org.apache.commons,nl.eur.eseor other examples. - artifactId: refers to a certain project. The combination of groupId and artifactId should be unique. Examples of an artifact id could be
commons-mathorpoi. - version: describes the version of the project. Since multiple versions of a project may be released over time, it is useful to state on which exact version of a library your project depends. That way, it is not possible that when a new version of library is released, your project may break because of some changes in the library.
Every project or library that you create, or which you can import as a dependency, defines these properties in its pom.xml file. Eclipse provides a graphical editor when you open the pom.xml file for your project. You can also edit the raw source code of the file. Typically, in the first section of the file, you will see something that looks as follows:
<modelVersion>4.0.0</modelVersion>
<groupId>nl.eur.ese.feb22012</groupId>
<artifactId>assignment3</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>Dataframe</name>
<description>Create your own dataframe!</description>As you can see, it contains a definition of the groupId, the artifactId and version of the project. In addition, it defines the version used in the model file, and gives a more readable name and description to the project.
The latter are useful, since no spaces or special characters are allowed in the groupId and artifactId. Note that the version definition in this example mentions the word SNAPSHOT.
This is usually indicate that the current version is still work in progress. When developers of software projects and libraries are satisfied with a version of their project, they can archive a copy of the project and remove the SNAPSHOT part of the version to indicate a final release of a certain version.
Note that in your private project and your assignment work, this is not necessary: you can leave the version on 0.0.1-SNAPSHOT as long as you like.
In the next section, there are usually some project properties defined. One useful property to define is the version you intend to use. The official names assigned to versions 5 to 8 are 1.5, 1.6, …1.8.
For Java versions after , the official versions are 9, 10, 11, etcetera. Hence we can configure a Maven project to be a project as follows:
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>If you create a new Maven project from scratch, it is possible that no version of the language is specified. Eclipse has a tendency to default to in case these properties are missing. Even if you add the properties, Eclipse will not automatically reconfigure your project to use a more modern version of Java: you have to tell Eclipse to update the project configuration. This can be done by right-clicking on the root of the project folder. In the context menu, choose Maven, then Update Project... and make sure the project is selected before you click OK. After Eclipse is done updating, you should be able to use the newer features of the version you selected.
After the definition of the project identity and the properties in the
project, the pom.xml usually contains the definition of dependencies.
This section looks as follows:
<dependencies>
<!-- Apache Math Commons -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
<!-- any number of dependency definitions can follow -->
</dependencies>In XML, comments are contained between <!– and –> symbols. Within the dependencies definition above, a single dependency is defined, which refers to the groupId, artifactId and version 3.6.1 of the Apache Commons Math library.
This instructs the Maven plugin of Eclipse that it should download the Apache Commons Math library with this particular version (if it has not already done so before) and all its dependencies, and add it to our project.
If we want to add more libraries, we can just add more <dependency> ... </dependency> definitions underneath the first one, as long as they are contained between the <dependencies> and </dependencies> tags of the file.
Alternatively, you can use Eclipse’s graphical editor for the pom.xml file, which contains a tab “Dependencies” that allow you to add dependencies by entering a groupId, an artifactId and a version of the libraries you want to add to your project.
When you add dependencies to your project, usually the required libraries are immediately added and downloaded by Eclipse. In some cases, it may run into trouble, for example if an internet connection is not available to download the libraries you requested. In such cases, it often helps to force Eclipse to attempt and download the libraries again at a later moment. This can be done by clicking with the right mouse button on the root project folder and choosing Maven → Update Project... from the context menu. In the dialog, make sure you select the current project and enable the checkbox “Force Update of Snapshots/Releases”.
Now that we discussed how libraries and dependencies can be added to a Java project, the next step is to start using those libraries.
Using a Library
When you import a new library, you usually have a good reason: you want to use the functionality offered by the library. For example, you added Apache Math Commons because you want to perform computations that rely on linear algebra, you added XChart since you want to make plots, or added Apache POI since you want to read or write Excel files. So, often, your main goal is clear. However, it is not always immediately obvious what code you need to write to reach this goal. In this section, we provide some tips how you can learn more about a library.
When you add a library, most of the time you will need to figure out how to obtain objects from classes in the library. When you are interested in linear algebra, you should figure out how to obtain objects that represent matrices and vectors. When you want to work with a plotting library, you should figure out how to obtain objects that represents plots. There are three common ways in which objects can be obtained: by calling constructors, by calling static factory methods and finally by calling methods on other objects, for example by means of the Builder pattern.
When you have obtained some object, you should figure out what you can do with objects from the library. When you use a good IDE such as Eclipse, you often can make use of the auto completion function of your editor to find out which methods are available on the objects. If a library is well designed, you can often guess what a method does by inspecting the name of the method and its arguments, as well as the types of the arguments and the return types. If this turns out to be difficult or inconvenient, it often a good idea to study the Javadoc API documentation of the library, as it typically documents all public methods available within the library.
It is often helpful to figure out to look at the manual of the library and see if they have any quick introduction, user guide or example code. These things can usually be found on the website of the more professional libraries that are available. Good examples are often extremely helpful if you need a quick and brief introduction of how to obtain results with the library.
Finally, an important piece of advice is: experiment! Try writing short programs that call and use the library, and see if the results and behavior are similar to what you expect. Sometimes libraries seem to be intuitive in their usage, but they may exhibit unexpected behavior, in particular if you do not inspect that documentation that describes the behavior of the classes in the library.
Apache Commons Math
The Apache Commons Math library provides many classes to perform various mathematical tasks. While it is not in all cases the fastest or most accurate library available, it provides a versatile set of methods that are often decent and typically easy to use. An advantage is also that it is a pure Java library: all the code is written in Java, and runs on all devices that can run Java. There exist libraries that provide faster linear algebra computations, but those often rely on highly optimized non-Java code, which must be adapted for different devices and operating systems you may want to run the code on.
The website of the Math Commons project contains a decent User Guide. The library contains a number of interesting packages, some of which we will discuss in the following sections.
Linear Algebra
Apache Math Commons contains a package for linear algebra, org.apache.commons.math3.linear.
This library provides a number of implementations of the RealMatrix interface, that models a matrix over real numbers. For example, the class Array2DRowRealMatrix uses a two-dimensional array to store a matrix, whereas the class OpenMapRealMatrix uses a sparse representation that only stores non-zero entries of the matrix (but behaves differently in some corner cases than a regular matrix).
The class MatrixUtils provides a number of useful static factory methods we can use to create matrices in such a way that we do not need to choose which class is used to represent the matrix. The following example code shows us how two create two matrices and multiply them:
// Factory method that creates a 3 by 3 matrix
RealMatrix matrix = MatrixUtils.createRealMatrix(3,3);
// Change entries in the matrix
matrix.setEntry(0, 1, 3);
matrix.setEntry(1, 2, 4);
matrix.setEntry(2, 0, 5);
// Print the matrix
System.out.println(matrix);
// Create a second matrix using a constructor directly
double [][] data = new double [][] {{0.2, 0.3, 0.4}};
RealMatrix matrix2 = new Array2DRowRealMatrix(data);
// Compute the result of a matrix multiplication
RealMatrix matrix3 = matrix2.multiply(matrix);
System.out.println(matrix3);Distributions
Another useful package in the Math Commons library is org.apache.commons.math3.distribution which contains the interfaces RealDistribution and IntegerDistribution that define many useful operations we can perform on operations, such as cumulativeProbability, probability and sample.
The package also provides a large number of classes that provide implementations for these interfaces, such as UniformRealDistribution, UniformIntegerDistribution, NormalDistribution, PoissonDistribution or BinomialDistribution.
The following code gives an example of how these distributions can be used:
// RealDistribution example
RealDistribution d1 = new UniformRealDistribution(20,40);
System.out.println(d1.cumulativeProbability(30));
System.out.println(d1.sample());
// IntegerDistribution example
IntegerDistribution d2 = new BinomialDistribution(10,0.6);
System.out.println(d2.cumulativeProbability(3));
System.out.println(d2.cumulativeProbability(4));
System.out.println(d2.probability(4));
System.out.println(d2.sample());Executing the above code could print the following (note that the random samples may differ for each run):
Note that the RealDistribution and IntegerDistribution interfaces provide more useful methods, including methods that support the reseeding of the random number generator used to produce samples.
Statistical Testing
The package org.apache.commons.math3.stat.inference provides a number of classes that can perform hypothesis testing, including classes such as BinomialTest, KolmogorovSmirnovTest and TTest.
It is possible to create an object by calling the constructor of these classes, and then perform a test by calling a method on that object. Alternatively, the package provide a utility class TestUtils that provides static methods for some of the tests.
These static methods typically allow you to avoid the creation of a test object. Two examples of how statistical tests can be performed can be found in the text below:
// Perform a Binomial test using a BinomialTest object
BinomialTest biTest = new BinomialTest();
int trials = 15;
int successes = 3;
double probability = 0.5;
AlternativeHypothesis alt = AlternativeHypothesis.LESS_THAN;
double pValue = biTest.binomialTest(trials, successes, probability, alt);
System.out.println(pValue);
// Perform a t-Test using a TestUtils utility method
double [] sample = new double[] {1.0, 2.0, 4.0, 4.0, 5.0, 6.0};
pValue = TestUtils.tTest(4, sample);
System.out.println(pValue);which should print:
XChart
Another feature commonly required when working with quantitative data is plotting functionality. One Java library that provides ways to plot data is the XChart library, which is relatively easy to use to make plots, but also has many options for customization of the plots.
The main classes of the library can be found in the package org.knowm.xchart, for which Javadoc documentation is available.
In general charts have many customization options, which makes defining constructors for them sometimes rather complicated, as they would require many arguments. The disadvantage of having constructors with many arguments that have similar types, is that it becomes hard to remember for a user of that class in which order all arguments should be passed. A common way to avoid that issue is to use the Builder pattern.
The Builder pattern involves three steps. In the first step, we create a builder object that will help us construct the object we are actually interested in. We then perform a number of chained calls to methods that refer to names of arguments we want to provide to the builder, and that should be used to construct the object we want. Finally, we call the build() method to construct the actual object.
The XChart library provides a number of useful chart types, such as the XYChart, which can be used to produce scatter plots and line plots, as well as the CategoryPlot, that can be used to produce bar charts and histograms. If we want to create an XYChart, one way to do it is by means of an XYChartBuilder. The syntax for this would look as follows:
// Obtain a chart builder
XYChartBuilder builder = new XYChartBuilder();
// Define properties we want, and obtain a XYChart class by calling build
XYChart chart = builder.xAxisTitle("time")
.yAxisTitle("stock price")
.theme(ChartTheme.Matlab)
.build();Note that using the builder, we now clearly defined three properties of our XYChart: the title of the x-axis, the title of the y-axis and the theme we want to use. These property definition method calls are chained, and the final call we use is the build() method, which produces the actual XYChart object we are interested in.
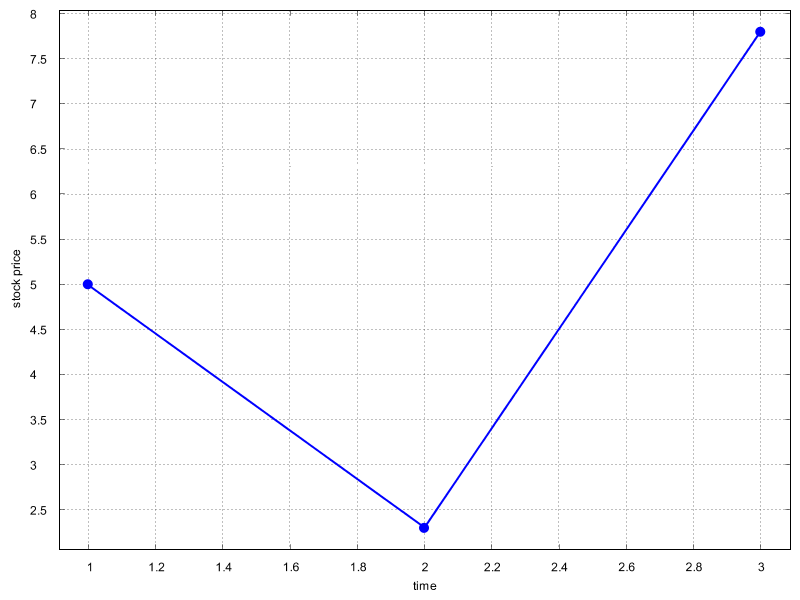
Note that no data to plot is provided yet. To add actual data, we should use the addSeries() method, which adds a series of data. In an XYPlot, a series typically consists of x-values and y-values for the data. For example, if we want to plot the stock prices over time for multiple companies, each company would have a vector of times (the x-values), the prices of the stock (the y-values) and a name of the company. In the following example code, we add some data to the XYChart object we constructed previously.
// Define data
double [] xData = new double[] { 1.0, 2.0, 3.0 };
double [] yData = new double[] { 5.0, 2.3, 7.8 };
// Add a series to the chart
chart.addSeries("FancyCorp", xData, yData);Now our XYChart object contains relevant data. Before we visualize our plot, we should customize some styling properties.
In this particular example, we set the size of the markers to a large size, and we hide the legend that explains the meaning of each series, since we are only plotting a single series of data in this example.
We can customize styling options by calling the getStyler() method on our XYChart object, which gives access to an [XYStyler][] object which has many getter and setter methods related to style properties of our plot.
Using the following code, we customize the style of our plot:
// Change some styling properties
chart.getStyler().setMarkerSize(10);
chart.getStyler().setLegendVisible(false);Now that we created an interesting plot object, we can view our results by making the call new SwingWrapper<>(chart).displayChart();, which shows a resizable window with the chart. Alternatively, we can save the plot to a image file using a static method from the BitmapEncoder class as follows:
// Write the chart to a file
BitmapEncoder.saveBitmap(chart, "my-chart.png", BitmapFormat.PNG);Note that we need to deal with a potential IOException when calling this method. The filename is passed as a String object, can be either a relative path (as in the example) or a absolute path. The figure below shows the resulting image which is written in the lossless PNG format.
For the creation of a histogram, you should use a CategoryChart object that can be constructed using a CategoryChartBuilder.
In order to convert a double [] to series data that can be pass to a CategoryChart, the Histogram class can help to construct a plot based on a given number of bins.
The website of XChart contains example code for this and many other kinds of plots. It is highly recommended to investigate these examples if you are interested in plotting using this library.
Apache POI
The final library we discuss is the Apache POI library, which provides a Java API for Microsoft Office Documents. If you work with quantitative data and want to be able to open your data using Microsoft Excel (or similar Spreadsheet software), you can use csv files. However, those files have a disadvantage, as the way they are treated by Excel depends on the regional settings of the operating system.
Thus, a computer that has its regional settings configured to United States may read in different numbers and values than a computer that has its regional settings configured to The Netherlands.
This issue can be avoided by using the default file format of Microsoft Excel, xlsx, but this is too complicated to read and write by hand. The Apache POI library can take care of this. Its website has many code examples that showcase its many features. It is also possible to read more details in the Javadoc documentation of the library.
Microsoft Excel is the world’s most popular Spreadsheet application. Spreadsheets consist of three main components: a workbook corresponds to a spreadsheet file, which may contain multiple sheets that appear in Excel as tabs at the bottom of the application. Each sheet contains a table of cells. Each cell has a row and column index that make up the address of the cell, and can contain either a value (textual or numeric), or a formula that defines how the value should be computed based on other cells. The figure below shows a screenshot of an Microsoft Excel workbook and points out where you can choose the active sheet, and highlights a single cell.
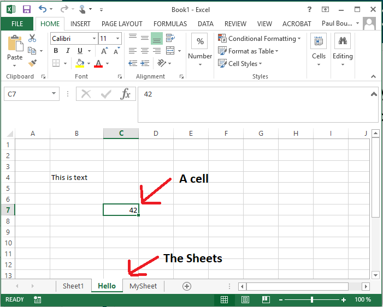
In Apache POI, a workbook is modeled by the Workbook interface. This interface contains methods to list, access and create new sheets in the workbook. Methods on the workbook such as getSheetAt(int index), getSheet(String name) and createSheet() can produce Sheet objects.
The Workbook interface also extends the Iterable<Sheet> interface, so it is possible to use an enhanced for loop to iterate over all Sheet objects that are contained within a Workbook.
A Sheet object represents a sheet in a workbook. The data within a Sheet object is always organized in rows.
To access particular cell objects in a sheet, we first need access to a Row. In a clean, new Sheet object, no row objects are present yet.
If the Sheet object does not contain a Row object that corresponds to a particular row index, that means no cells and cell data is present in that row. Row objects can be obtained either by calling the getRow(int rownum) method or the createRow(int rownum) method on a Sheet object.
Note that if you create a row that already exists, old row including all its cell data is overwritten.
Alternative, the Sheet interface extends the Iterable<Row> interface, and it is thus possible to use the enhanced for loop to iterate over all Row objects present in a particular Sheet object.
A Row objects represents a particular row in a sheet, and contains a number of Cell objects. These Cell objects represent the actual cells in a sheet, that can either hold values or formulas.
Cell objects can be obtained from a Row object, either by calling the createCell(int colnum) method or the getCell(int colnum) method.
Note that if you create a cell that is already present, the old cell including its data is overwritten.
Furthermore, the Row interface extends the Iterable<Cell> interface, so it is possible to use the enhanced for loop to iterate over all Cell objects present in a row.
If we have a Cell object, we can set a new value to that cell by calling the setCellValue(double value) or the setCellValue(String value) methods on it.
Alternatively, it is possible to set a formula for the cell by calling the setCellFormula(String formula) method.
Finally, we can check what type of data the Cell currently holds by calling the getCellType() method on the Cell.
This method returns a CellType object. To check if a Cell cell currently holds a numeric value or a text value using the following example code:
if (cell.getCellType() == CellType.NUMERIC) {
double value = cell.getNumericCellValue();
System.out.println("Number: "+value);
}
else if (cell.getCellType() == CellType.STRING) {
String value = cell.getStringCellValue();
System.out.println("Text: "+value);
}Note that this example ignores values that were computed using a formula, as that results in a different cell type. We can also access other properties of the Cell using the various methods available in the Cell interface, including the methods getRowIndex() and getColumnIndex().
Writing Spreadsheets
In order to create a new xlsx file that can be opened using Microsoft Excel, it is necessary to use the class XSSFWorkbook, which implements the Workbook interface.
The Workbook interface has a method write(OutputStream os), that can be used to write a Workbook object to a file. A XSSFWorkbook object is considered a resource, so it is advisable to use a try-with-resources block when we want to write or read spreadsheet files.
The following example code opens a FileOutputStream for the file myfile.xlsx, creates a new workbook with a single sheet that has a single row with two cells, and writes that workbook to this file.
try (Workbook wb = new XSSFWorkbook(); OutputStream out = new FileOutputStream(new File("myfile.xlsx")))
{
Sheet mySheet = wb.createSheet();
Row firstRow = mySheet.createRow(0);
Cell c1 = firstRow.createCell(0);
Cell c2 = firstRow.createCell(0);
c1.setCellValue(42);
c2.setCellValue("Hello");
wb.write(out);
}Reading Spreadsheet
In order to read data from an xlsx file, we can pass a InputStream object to the constructor of the XSSFWorkbook class.
While there is also a constructor in XSSFWorkbook that accepts a file directly, any modification to cells are immediately written, and if you fail to correctly close the Workbook resource, all data in your spreadsheet may be lost.
By using an InputStream instead, you protect yourself from this potential harmful behavior of Apache POI.
The following example code opens the spreadsheet stored in file readthis.xlsx, obtains the first sheet in the workbook, and iterates over all rows and cells of that sheet:
//Note: use FileInputStream to avoid POI deleting or clearing the spreadsheet file!!
try (Workbook wb = new XSSFWorkbook(new FileInputStream(new File("readthis.xlsx"))) {
Sheet firstSheet = wb.getSheetAt(0);
for (Row r : firstSheet) {
for (Cell c : r) {
int row = c.getRowIndex();
int col = c.getColumnIndex();
if (c.getCellType() == CellType.NUMERIC) {
double val = c.getNumericCellValue();
System.out.println(row+", "+col+" : "+val);
}
else {
System.out.println(row+","+col+" : "+c.getCellType());
}
}
}
}